
Teaching Computers to Read the Room
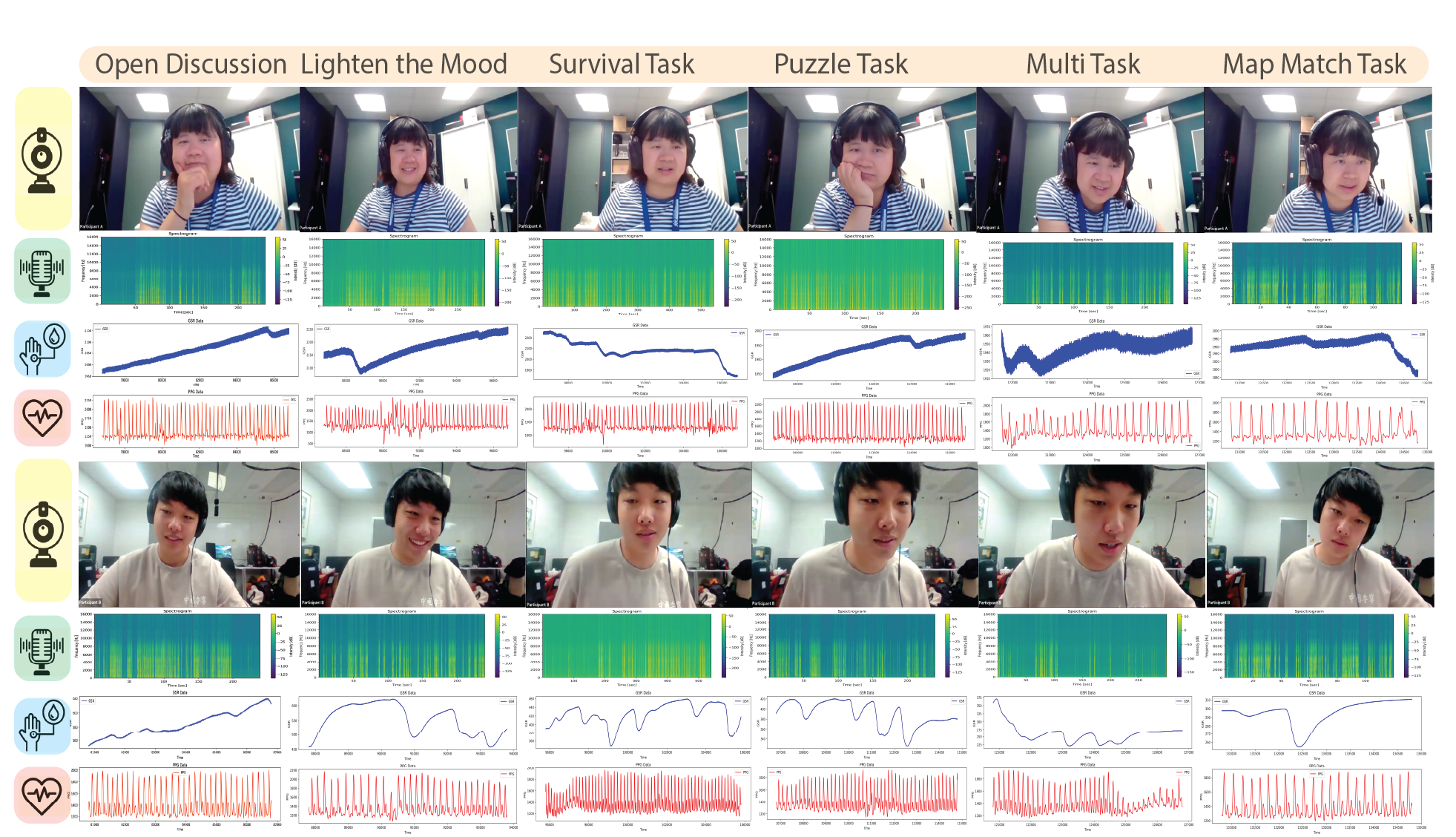
In simple terms: CoAffinity is like a textbook for teaching AI to understand how you're feeling during video calls. I collected data from 39 people doing collaborative tasks over 38+ hours, capturing everything from their facial expressions to their heart rate. Now computers can learn to "read the room" in virtual meetings.
🎯 Key Takeaways
- 38+ hours of multimodal data from 39 participants doing real collaborative tasks
- 82.6% accuracy in detecting cognitive load (how mentally taxed someone is)
- 80.2% accuracy in predicting emotional valence (positive vs. negative feelings)
- First dataset of its kind - combining affect and cognitive load in remote collaboration contexts
The Problem I Wanted to Solve
When the world shifted to remote work, I noticed something that bothered me: our video conferencing tools were essentially blind to how we were actually doing.
Think about it. In a physical meeting, a good manager notices when someone looks confused. They see the glazed-over eyes of someone who's been staring at spreadsheets for too long. They pick up on the tension when two people disagree. But Zoom? Teams? Google Meet? They just stream video, completely oblivious to the human dynamics unfolding.
A team member could be overwhelmed, disengaged, or struggling-and the technology wouldn't know or care.
This observation became the seed for CoAffinity.
Why I Built Another Dataset
You might wonder-don't we already have datasets for affective computing? We do. But here's the gap I identified:
Most existing datasets capture emotions in isolated contexts-watching videos alone, performing solo tasks, or responding to stimuli in a lab. But collaboration is fundamentally different. When we work together remotely, our cognitive load fluctuates based on:
- The complexity of the shared task
- Communication breakdowns (can you hear me? you're muted!)
- Technical issues (screen sharing not working... again)
- Social dynamics we can't fully perceive through a screen
- The exhaustion of trying to read people through tiny video windows
I wanted to capture this messy, real-world complexity that existing datasets missed.
How I Built It
Building CoAffinity meant solving several hard problems simultaneously:
1. Multimodal Synchronization
We collected:
- Video streams - facial expressions, gaze patterns, head movements
- Audio features - voice tone, speaking patterns, turn-taking dynamics
- Physiological signals - heart rate (PPG), skin conductance (GSR)
- Self-reports - continuous annotations of subjective experience
Synchronizing all these streams with millisecond precision across participants in different locations was challenging. A few milliseconds of drift could make the data useless for training ML models.
2. Ecological Validity
Lab studies are controlled but artificial. Nobody actually collaborates the way they do in a psychology lab. So I designed tasks that mirror real collaborative work:
- Brainstorming sessions - generating ideas under time pressure
- Problem-solving tasks - working through complex scenarios together
- Decision-making exercises - reaching consensus with limited information
These created the natural fluctuations in cognitive load and emotion that make the dataset valuable.
3. Ground Truth Labels
Here's a fundamental challenge: cognitive load and affect are internal states. How do you get reliable labels for something you can't directly observe?
We combined three approaches:
- Continuous self-reports - participants indicated their state at regular intervals
- Post-task questionnaires - NASA-TLX for workload, SAM for affect
- Physiological markers - heart rate variability and skin conductance as objective indicators
Cross-validating these sources gave us more reliable ground truth than any single method could provide.
What Makes This Dataset Special
| Feature | CoAffinity | Previous Datasets |
|---|---|---|
| Context | Real-time collaboration | Solo tasks or passive viewing |
| Data Sources | Video + Audio + Physio + Self-report | Usually 1-2 modalities |
| Duration | 38+ hours | Typically <10 hours |
| Cognitive Load Labels | Yes | Rarely included |
| Collaborative Tasks | Yes | No |
What CoAffinity Enables
With this dataset, researchers can now:
- Train models that detect when remote collaborators are struggling
- Design adaptive interfaces that respond to team cognitive states
- Build AI facilitators (like CLARA!) that support group cognition
This directly feeds into my PhD research on AI-augmented collaborative cognition. Imagine a virtual meeting assistant that notices when the team's collective cognitive load is spiking and suggests a break-or identifies that someone hasn't contributed in a while and creates space for them.
That's not science fiction anymore. CoAffinity makes it trainable.
The Results That Surprised Me
When I trained baseline models on CoAffinity, I was honestly nervous. Real-world data is noisy. Collaborative settings add complexity. Would the signals even be detectable?
The results exceeded my expectations:
- Cognitive load detection: 82.6% F1-score
- Valence prediction: 80.2% accuracy
- Arousal prediction: Strong correlation with physiological ground truth
These aren't perfect numbers, but they're good enough to be useful. Good enough to build systems that can actually help people.
📚 Personal Reflections: What I Learned
Creating CoAffinity taught me several things that changed how I approach research:
1. Design Decisions Are Everything
The hardest part of research isn't the technical implementation-it's the design decisions. Every choice shapes what questions the dataset can answer:
- Which sensors? (We chose PPG and GSR for their balance of signal quality and wearability)
- How many participants? (39 gave us statistical power without being logistically impossible)
- What tasks? (Collaborative tasks that mirror real work, not artificial lab exercises)
Getting these decisions right required understanding both the technical constraints and the eventual use cases.
2. Collaboration Teaches You What You Don't Know
This work wouldn't exist without my co-authors-Kunal, Yun Suen, Huidong, and Mark-each bringing expertise I lacked. Kunal's deep knowledge of affective computing. Yun Suen's experience with physiological sensing. Huidong's work on remote collaboration. Mark's decades of perspective on where the field is heading.
Research is a team sport, and CoAffinity made that viscerally clear.
3. The Gap Between "Working" and "Published" Is Huge
I had working data collection pipelines a year before the paper was published. The gap was filled with cleaning data, debugging synchronization issues, running baseline experiments, writing and rewriting, reviewer responses, and countless iterations.
But that gap is where the work becomes trustworthy. Quick results that can't withstand scrutiny don't help anyone.
What's Next?
CoAffinity is published in IEEE Transactions on Affective Computing, one of the premier journals in the field. But this is just the foundation. I'm now using insights from this dataset to design AI systems that can:
- Predict team cognitive overload before it causes breakdowns
- Adapt meeting dynamics in real-time based on group state
- Personalize support based on individual cognitive styles
The future of remote work isn't just about better video quality-it's about technology that truly understands and supports human collaboration.
And that future starts with data that captures what collaboration actually looks like.